◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。
Kohya 对 FLUX LoRA (B GPU) 和 DreamBooth / Fine-Tuning (B GPU) 训练带来了巨大改进
ID:21524 / 打印您可以下载所有配置和完整说明
https://www.patreon.com/posts/112099700 - 微调帖子 https://www.patreon.com/posts/110879657 - LoRA 帖子
Kohya 对 FLUX LoRA 和 DreamBooth / Fine-Tuning(最低 6GB GPU)训练带来了巨大的改进。
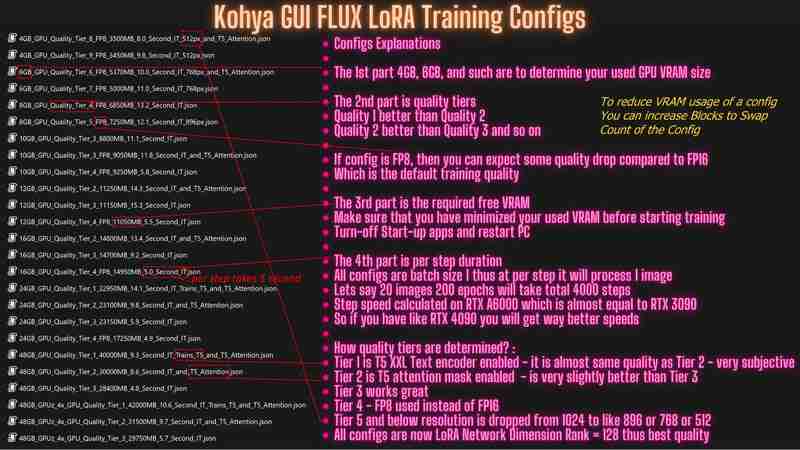
现在低至 4GB GPU 就可以以良好的质量训练 FLUX LoRA,24GB 及以下 GPU 在进行 Full DreamBooth / Fine-Tuning 训练时获得了巨大的速度提升
您至少需要 4GB GPU 才能进行 FLUX LoRA 训练,至少需要 6GB GPU 才能进行 FLUX DreamBooth / Full Fine-Tuning 训练。真是令人兴奋。
您可以在 > 下载所有配置和完整说明 https://www.patreon.com/posts/112099700
上面的帖子还提供了适用于 Windows、RunPod 和 Massed Compute 的一键安装程序和下载程序
模型下载器脚本也已更新,在 Massed Compute 上下载 30+GB 模型总共需要 1 分钟
您可以在这里阅读最近的更新:https://github.com/kohya-ss/sd-scripts/tree/sd3?tab=readme-ov-file#recent-updates
这是 Kohya GUI 分支:https://github.com/bmaltais/kohya_ss/tree/sd3-flux.1
减少 VRAM 使用的关键是使用块交换
Kohya 实现了 OneTrainer 的逻辑,显着提高了块交换速度,现在也支持 LoRA
现在您可以在 24 GB 及以下 GPU 上使用 LoRA 进行 FP16 训练
现在您可以在 4 GB GPU 上训练 FLUX LoRA - 关键是 FP8、块交换和使用某些层训练(记住单层 LoRA 训练)
我花了 1 天多的时间来测试所有较新的配置、它们的 VRAM 需求、它们的相对步进速度并准备配置:)